How Do the Search Engines Actually Work? Why You Should Care ( 2018 tips and tricks
Search engines allow users to search the internet for content using keywords. Although dominated by a few, there are several search engines that people can use. When a user enters a keyword or key phrase into a search engine, a search engine results page (SERP) is returned, ranking the found pages in order of their relevance. How this ranking is done differs across search engines.

Search engines often change their algorithms (the programs that rank the results) to improve user experience. They aim to understand how users search and give them the best answer to their query. This means giving priority to the highest quality and most relevantpages.
It’s not an exaggeration to say that we reached a point that we depend on search engines for almost anything we do.

And the reason this is happening is very simple. We know that search engines and in particular Google, has answers to all our questions and queries.
What happens though when you type a query and click search? How do search engines work internally and how do they decide what to show in the search results and in what order?
If you are a developer, designer, small business owner, marketing professional, website owner or thinking of creating a personal blog or website for your business, then you need to understand how search engines work.
Why?
Having a clear understanding of how search works, can help you create a website that search engines can understand, and this has a number of added benefits.
It’s the first step you need to take before even dealing with Search Engine Optimization (SEO) or any other SEM (Search Engine Marketing) tasks.
How do search engines work?
Search engines use programs, often referred to as spiders, robots or crawlers, to search the internet. These programs are used by search engines to build an index of the internet. However, although most search engines will provide tips on how to improve your page ranking, the exact algorithms used are well guarded and change frequently to avoid misuse. But by following a few well accepted search engine optimisation (SEO) techniques you can ensure that your website is well indexed and remains high in the rankings.
Different search engine methods
Each of the three main search engines use different methods to rank websites. Understanding these methods will help you understand the SEO strategies outlined in this guide.
The three main search engines are:
- Google - Google assesses the value of a webpage based on the number of backlinks ie links back to your website. Links from pages that are seen as important by Google weigh more heavily and increase the ranking of the linked pages. Google also analyses the relevancy of the content on the page and other factors like mobile-friendliness. The Google ranking algorithm changes constantly. It can be useful to keep up to date with the latest changes.
- Yahoo! - Yahoo! began as a manually edited directory. It now uses link analysis tools to determine page relevancy, though content is also important in deciding search relevance. Other factors that are important include backlinks and a good site design.
- Bing - Microsoft's Bing search engine ranks websites based on the webpage content, the number and quality of websites that link to your pages, and the relevance of your website's content to keywords.
Search engines are complex computer programs.
Before they even allow you to type a query and search the web, they have to do a lot of preparation work so that when you click “Search”, you are presented with a set of precise and quality results that answer your question or query.
What does the ‘preparation work’ includes? Two main stages. The first stage is the process of discovering the information and the second stage is organizing the information so that it can be used later for search purposes.
This is generally known in the Internet World as Crawling and Indexing.
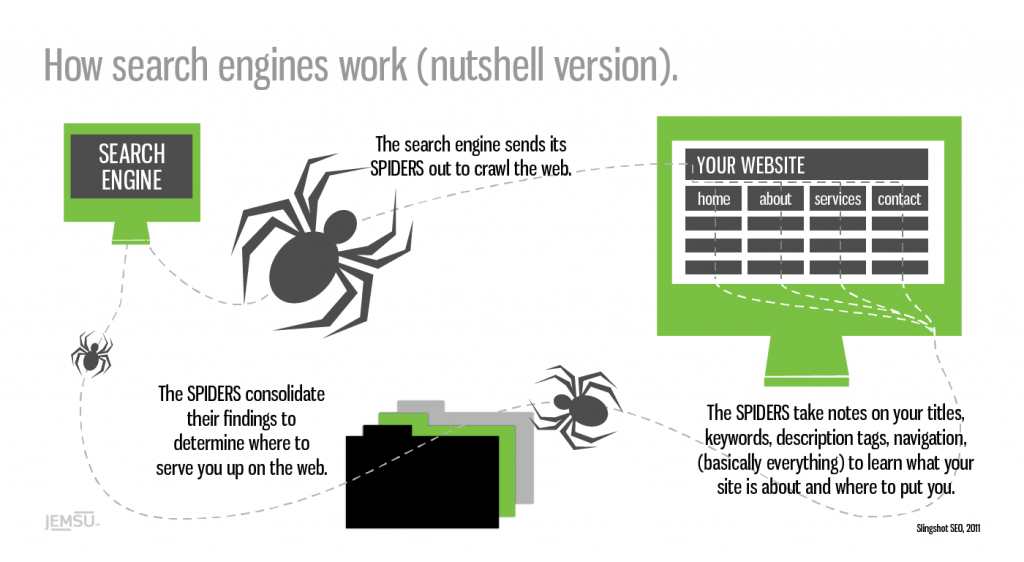
Crawling
Search engines have a number of computer programs called web crawlers (thus the word Crawling), that are responsible for finding information that is publicly available on the Internet.
To simplify a complicated process, it’s enough for you to know that the job of these software crawlers (also known as search engine spiders), is to scan the Internet and find the servers (also known as webservers) hosting websites.
They create a list of all the webservers to crawl, the number of websites hosted by each server and then start work.
They visit each website and by using different techniques, they try to find out how many pages they have, whether it is text content, images, videos or any other format (css, html, javascript, etc).
When visiting a website, besides taking note of the number of pages they also follow any links (either pointing to pages within the site or to external websites), and thus they discover more and more pages.
They do this continuously and they also keep track of changes made to a website so that they know when new pages are added or deleted, when links are updated, etc.
If you take into account that there are more than 130 trillion individual pages on the Internet today and on average thousands of new pages are published on a daily basis, you can imagine that this is a lot of work.
Why care about the crawling process?
Your fist concern when optimizing your website for search engines, is to ensure that they can access it correctly otherwise if they cannot ‘read’ your website, you shouldn’t expect much in terms of high rankings or search engine traffic.
As explained above, crawlers have a lot of work to do and you should try and make their job easier.
There are a number of things to do to make sure that crawlers can discover and access your website in the fastest possible way without problems.
- Use Robots.txt to specify which pages of your website you don’t want crawlers to access. For example, pages like your admin or backend pages and other pages you don’t want to be publicly available on the Internet.
- Big search engines like Google and Bing, have tools you can use to give them more information about your website (number of pages, structure, etc) so that they don’t have to find it themselves.
- Use an xml sitemap to list all important pages of your website so that the crawlers can know which pages to monitor for changes and which to ignore.
Indexing
Crawling alone is not enough to build a search engine.
Information identified by the crawlers needs to be organized, sorted and stored so that it can be processed by the search engine algorithms, before made available to the end user.
This process is called Indexing.
Search engines don’t store all the information found on a page in their index but they keep things like: when it was created / updated, title and description of the page, type of content, associated keywords, incoming and outgoing links and a lot of other parameters that are needed by their algorithms.
Google likes to describe their index like the back of a book (a really big book).
Why care about the indexing process?
It’s very simple, if your website is not in their index, it will not appear for any searches.
This also implies that the more pages you have in the search engines indexes, the more are your chances of appearing in the search results when someone types a query.
Notice that I mentioned the word ‘appear in the search results’, which means in any position and not necessarily on the top positions or pages.
In order to appear in the first 5 positions of the SERPS (search engine results pages), you have to optimize your website for search engines using a process called Search Engine Optimization or SEO in short.
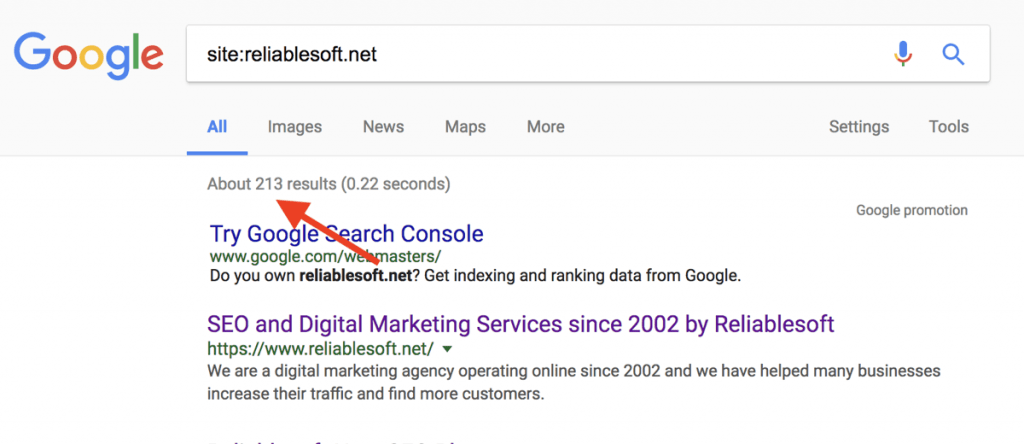
How to find how many pages of your website are included in the Google index?
There are two ways to do that.
Open Google and use the site operator followed by your domain name. For example site:reliablesoft.net. You will find out how many pages related to the particular domain are included in the Google Index.
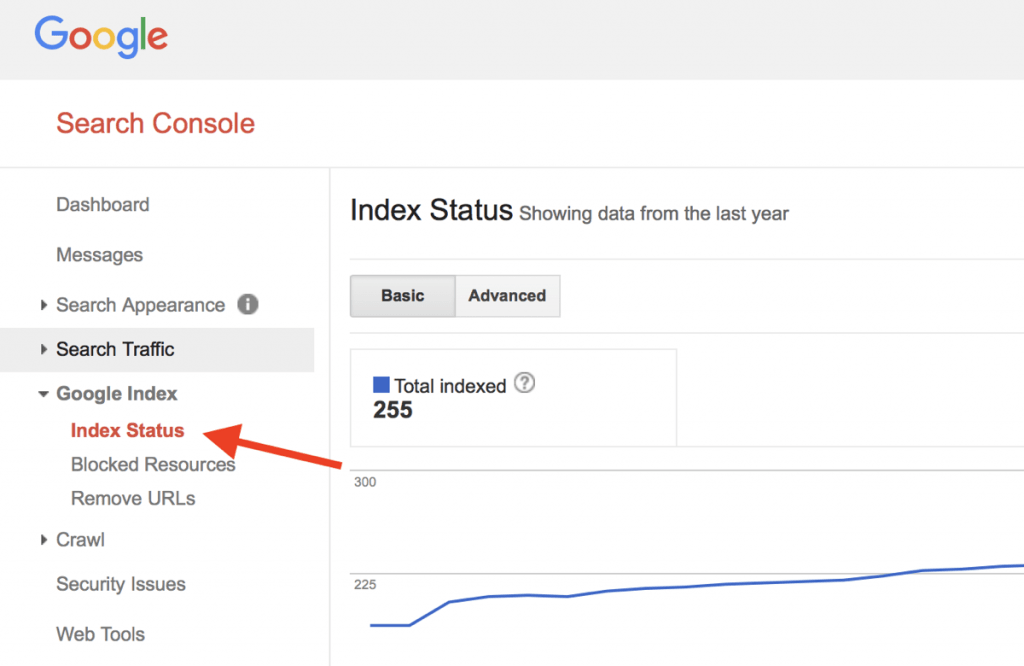
The second way is to create a free Google Search Console account and look at the Index Status report.
Search Engine Ranking Algorithms
The third and final step in the process is for search engines to decide which pages to show in the SERPS and in what order, when someone types a query.
This is achieved through the use of search engine ranking algorithms.
In simple terms, these are pieces of software that have a number of rules that analyze what the user is looking for and what information to return.
These rules and decisions are made based on what information is available in their index.
How do search engine algorithms work?
Over the years search engine ranking algorithms have evolved and became really complex.
At the beginning (think 2001) it was as simple as matching the user’s query with the title of the page but this is no longer the case.
Google’s ranking algorithm takes into account more than 255 rules before making a decision and nobody knows for sure what these rules are.
And this includes Larry Page and Sergey Bin (Google’s founders), who created the original algorithm.
Thinks have changed a lot and now machine learning and computer programs are responsible for making decisions based on a number of parameters that are outside the boundaries of the content found on a web page.
The table below shows in a schematic representation, the most common factors taken into account by search engine algorithms.
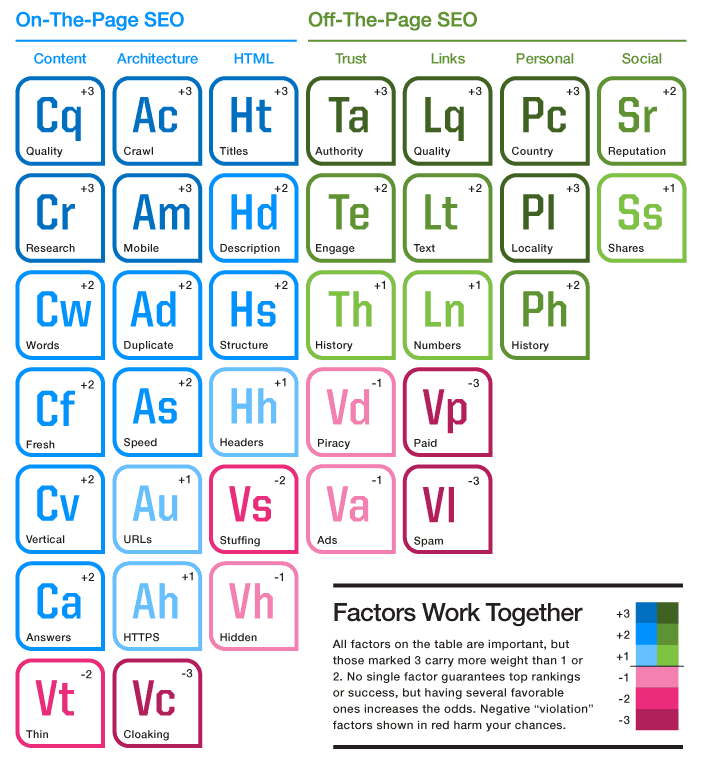
To make it easier to understand, here is a simplified process of how search engines ranking algorithms work:
Step 1: Analyze User Query
The first step is for search engines to understand what kind of information the user is looking for.
To do that, they analyze the user’s query by breaking it down into a number of meaningful keywords.
A keyword is a word that has a specific meaning and purpose.
For example, when you type “How to make a chocolate cake”, search engines know from the words how to that you are looking for instructions on how to make a chocolate cake and thus the returned results will contain cooking websites with recipes.
If you search for “Buy refurbished ….”, they know from the words buy and refurbished that you are looking to buy something and the returned results will include ecommerce websites and online shops.
Machine learning has helped them associate related keywords together. For example, they know that meaning of this query “how to change a light bulb” is the same as this “how to replace a light bulb”.

They are also clever enough to interpret spelling mistakes, understand plurals and in general extract the meaning of a query from natural language (either written or verbal in case of Voice search).
Step 2: Finding matching pages
The second step is to look into their index and decide which pages can provide the best answer for a given query.
This is a very important stage in whole process for both search engines and web owners.
Search engines need to return the best possible results in the fastest possible way so that they keep their users happy and web owners want their websites to be picked up so that they get traffic and visits.
This is also the stage where good SEO techniques can influence the decision made by the algorithms.
To give you an idea of how matching works, these are the most important factors:
Title and content relevancy – how relevant is the title and content of the page with the user query.
Type of content – if the user is asking for images, the returned results will contain images and not text.
Quality of the content – content needs to be thorough, useful and informative, unbiased and cover both sites of a story.
Quality of the website – The overall quality of a website matters. Google will not show pages from websites that don’t meet their quality standards.
Date of publication – For news related queries, Google wants to show the latest results so date of publication is also taken into account.
Popularity of a page – This doesn’t have to do with how much traffic a website has but how other websites perceive the particular page.
A page that has a lot of references (backlinks), from other websites is considered to be more popular than other pages with no links and thus has more chances in getting picked up by the algorithms. This process is also known as Off-Page SEO.
Language of the page – Users are served pages in their language and it’s not always English.
Webpage Speed – Websites that load fast (think 2-3 seconds) have a small advantage compared to websites that are slow to load.
Device Type – Users searching on mobile are served mobile friendly pages.
Location – Users searching for results in their area i.e. “Italian restaurants in Ohio” will be shown results related to their location.
That’s just the tip of the iceberg. As mentioned before, Google uses more than 255 factors in their algorithms to ensure that their users are happy with the results they get.
Pro tip: Everything is described in more details in The Complete SEO Guide, which also includes step-by-step instructions on how to optimize your pages.
Why care how search engine ranking algorithms work?
In order to get traffic from search engines, your website needs to appear in the top positions in the first page of the results.
It is statistically proven that the majority of users click one of the top 5 results (both desktop and mobile).
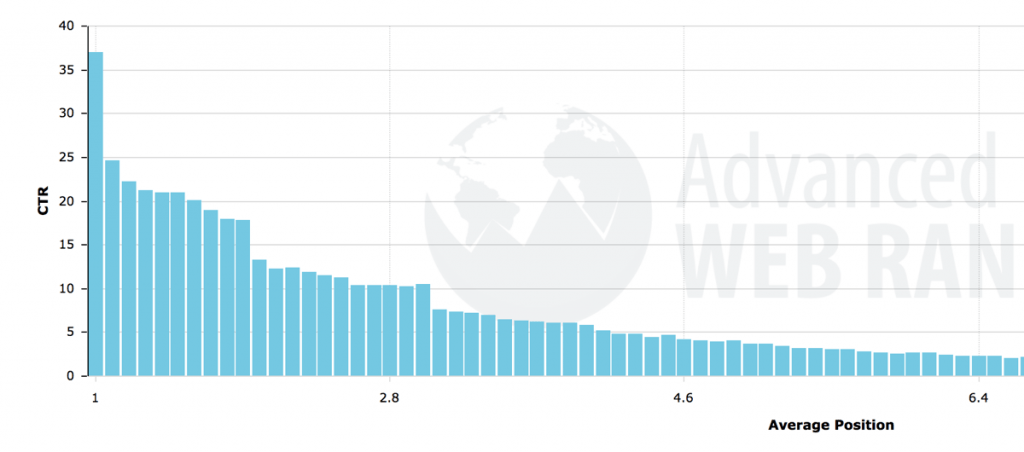
Appearing in the second or third page of the results will not get you any traffic at all.
Traffic is just one of the benefits of SEO, once you get to the top positions for keywords that make sense for your business, the added benefits are much more.
Knowing how search engines work can help you adjust your website and increase your rankings and traffic.

0 Response to "How Do the Search Engines Actually Work? Why You Should Care ( 2018 tips and tricks"
Post a Comment